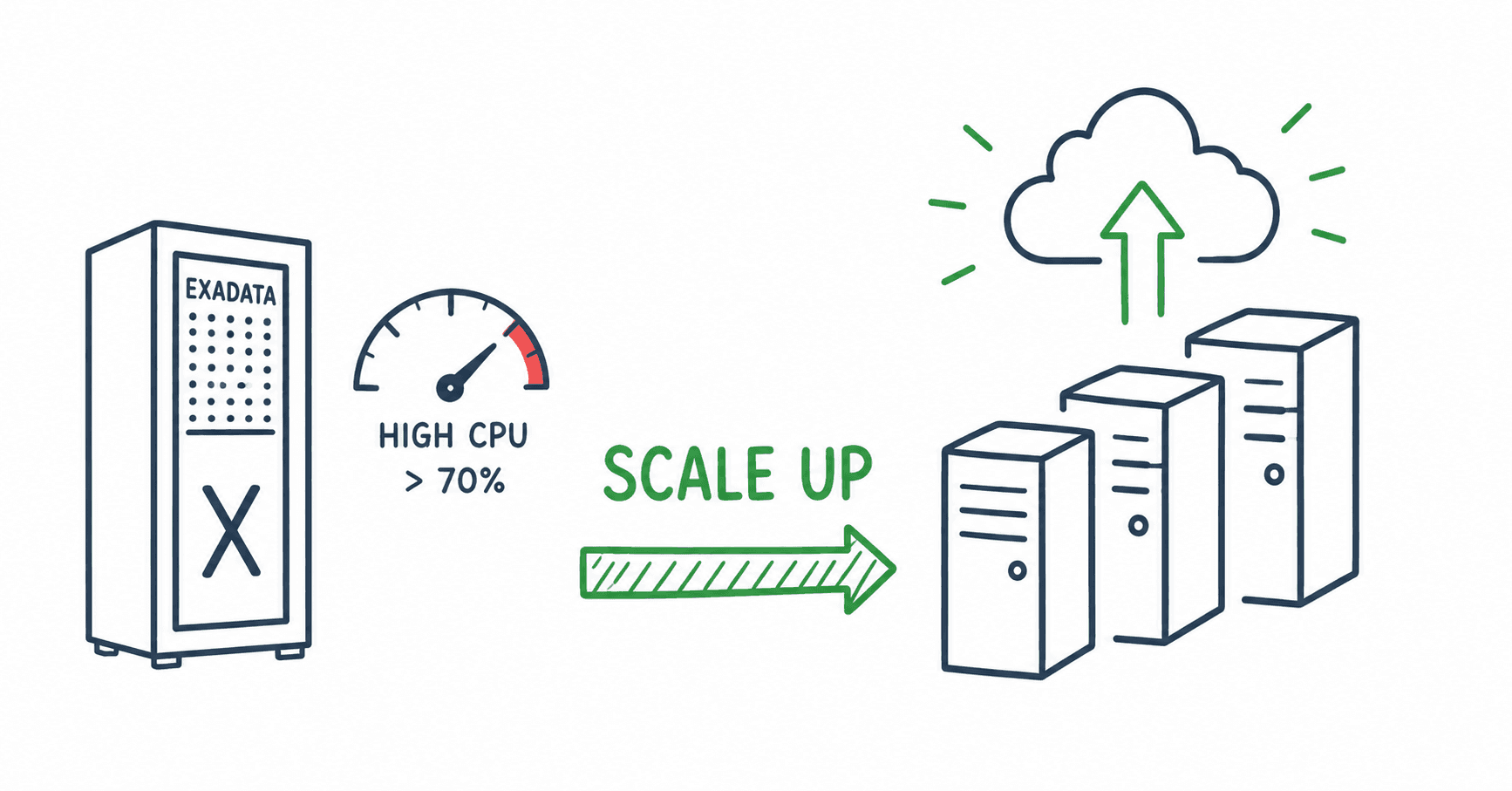
Get CPU load for automatic scale up on ExaCC
During the implementation of the automatic scale-up scripts for ExaCC, the part that, in theory, would be the simplest can be the most "complex," and I will briefly talk about that.
Regardless of the scale-up script you use, the point that actually triggers scaling up or down is the correct collection of the CPU load metric.
Normally, scripts use the metric from /proc/loadavg, but I faced a case where I needed something more sensitive, and then I remembered SAR. However, SAR had 2 problems: either it collected every 10 minutes, or it collected in real time, like sar 1 1. At moments of high CPU usage lasting only seconds, you might trigger an alert, so based on that, I thought of a way to have a shorter interval in historical data. So I simply decided to change SAR's collection interval from 10 minutes to 1 minute.
[root@exacc-01 ~]# cat /usr/lib/systemd/system/sysstat-collect.timer
# /usr/lib/systemd/system/sysstat-collect.timer
# (C) 2014 Tomasz Torcz <tomek@pipebreaker.pl>
#
# sysstat-11.7.3 systemd unit file:
# Activates activity collector every 10 minutes
[Unit]
Description=Run system activity accounting tool every 10 minutes
[Timer]
OnCalendar=*:00/1
[Install]
WantedBy=sysstat.service
The default for OnCalendar is OnCalendar=*:00/10, and I changed it to OnCalendar=*:00/1. This way, SAR collection became every 1 minute.
07:36:00 CPU %user
07:37:00 all 60.03
07:38:01 all 48.04
07:39:01 all 61.00
07:40:00 all 84.88
07:41:00 all 51.50
07:42:00 all 40.28
07:43:00 all 38.97
07:44:00 all 37.73
07:45:01 all 37.58
07:46:00 all 50.31
07:47:00 all 59.05
07:48:00 all 57.79
07:49:00 all 56.53
07:50:00 all 61.30
07:51:01 all 47.48
Based on these new collections, I was able to get higher accuracy in the values, thus correctly obtaining the average CPU usage for the last 2 minutes. So whenever ExaCC stays above 70%, for example, within 2 minutes, it performs a scale-up up to a specific threshold. Normally, there is a third machine that performs this check and triggers the scale-up, so below is the script I placed inside each node.
[opc@exacc-db01 scripts]$ cat GetLoad2.sh
#sar -u | awk '/^[0-9]/ {print \(3}' | tail -2 | awk '{sum+=\)1} END {printf "%.0f\n", sum/NR}'
#!/bin/bash
sar -u | awk '/^[0-9]/ {
if (\(2 == "AM" || \)2 == "PM")
print $4
else
print $3
}' | tail -2 | awk '{sum+=$1} END {printf "%.0f\n", sum/NR}'
In this way, you can use a third machine to trigger the alert.
[oracle@maquina_scale scaleup_scripts]\( CPU_USAGE1=\)(ssh -o ConnectTimeout=10 -o BatchMode=yes -i /home/oracle/.ssh/id_rsa opc@10.X.X.X /home/opc/scripts/GetLoad2.sh)
[oracle@maquina_scale scaleup_scripts]\( echo \)CPU_USAGE1
71
As mentioned earlier, the third machine triggers the scale and also checks each machine's threshold via SSH, thus obtaining the CPU value and being able to perform the correct ECPU or OCPU scaling.
That is it, everyone. With this, you can already have a good metric for your ExaCC to scale. This also works for ExaCS. Later on, I will bring some script models that I created to perform scale-up.